데이터 전달: The Big Picture

레지스터는 프로세서의 데이터 경로에 있습니다.
피연산자가 메모리에 있는 경우 프로세서(레지스터)에 로드하고
작동한 후 메모리에 다시 저장해야 합니다.
The "Memory Wall" (기억의 벽)
■ Processor vs DRAM 속도 격차가 계속 증가한다.
■ 우리가 원하는 것: 크고 빠른 메모리
■ 메모리 시스템은 1GB의 SRAM(1ns 접근시간)과 같은 성능을 발휘해야 합니다. 하지만 1GB의 느린 메모리와 같은 비용이 듭니다.
Key concept
계층적인 메모리 기술을 사용한다.
- CPU근처에 있는 메모리는 크기는 작더라도 속도는 빠른 것으로 하자.
- CPU와 멀리있는 메모리는 크기는 크고 속도는 느린 것으로 하자.
우수한 메모리 계층(캐시) 설계가 전반적인 성능에 점점 더 중요해지고 있음
■ 1980: μproc에 캐시 없음, ■ 1989: chip에 캐시가 있는 최초의 인텔 CPU
■ 1995: 칩 위의 2-레벨 캐시 ■ 2022: ?
좋은 아이디어: 지역성의 원리 / 메모리 계층

CPU : 레지스터 파일
물리 메모리: DRAM, SRAM
가상 메모리: 하드드라이버 구성, 크기는 크고 가격이 저렴하지만 속도는 느리다.(CPU와 거리가 먼 메모리!!)
* 집중적으로 접근하는 공간을 CPU근처에 두어 바로 실행하게끔 해주면 실행시간을 줄일 수 있다!!
지역성의 원리
"프로그램은 언제든지 주소 공간의 작은 부분에만 액세스할 수 있습니다."

l 임의로 액세스하는 장소는 아마 없을 것입니다.
■ Temporal Locality(시간 지역성)
l 접근된 항목은 곧 다시 접근될 가능성이 높다.
예: 루프의 명령 및 데이터
■ Spatial Locality (공간 지역성)
l 접근된 항목 근처의 항목이 곧 접근될 가능성이 높다.
예: 순차적 명령 액세스, 데이터 배열
지역성의 이점을 어떻게 활용하는가?
가장 최근에 접근한 데이터 항목을 프로세서에 더 가깝게 유지한다. (나중에 다시 사용될 가능성이 높기 때문이다.)

Caches , Main memory , Hard Disk
데이터 전달 : Cashes ← Main memory ← Hard Disk
- 작업 집합을 캡처하여 CPU에 가장 가까운 메모리에 보관
- 인접한 시간(△t)동안 동일한 공간이 계속 발생한다.
ex, stack에 △t부분을 보면 지그재그로 계속 발생하는 것을 알 수 있다.
- CPU의 값들이 캐시에 적중되서 메모리까지 전달되지 않아도 된다.
메모리 계층 수준: 용어
■ Block (or cashe line or cashe block) : 복사하는 단위
- 맨 먼저 캐시에서 원하는 내용을 찾으면 프로세서로 가져가서 실행한다.
- 접근된 데이터가 상위 레벨에서 찾게 되면 프로세서로 가져가서 실행하게 되는데, 이를 Hit(적중했다)라고 한다.
■ Hit time : 적중하는 시간
■ Hit ratio : 적중률 = #hits / #accesses → 평균 90%이상이다.
캐시에서 원하는 내용이 없으면 하위 레벨인 메인메모리로 내려가서 찾고, 메인메모리에도 없으면 하위 레벨인 하드디스크에서 찾아서 copy한다. 하위레벨로 내려갈수록 부담이 커진다.
■ page : 메인 메모리, 하드 디스크의 접근 단위
만약 원하는 결과가 없으면 Miss라고 한다.
■ Miss ratio : 실패율 = #misses / #accesses = 1 - Hit ratio
■ Miss penalty : 실패 손실, Miss가 발생할 때 생기는 부담, 상위 레벨에 없어서 하위레벨에서 찾아서 돌아오는 시간
Hit Time << Miss Penalty : 적중하는 시간보다 실패 손실이 훨씬 많으므로 실패손실을 줄여서(적중률을 높여서) 성능을 향상시킬 수 있다.
메모리 계층의 공통적인 프레임 워크
: 상위로 갈수록 page(block)은 용량이 작고 속도는 빠르다.
① block placement : Miss가 발생해서 하위에서 상위레벨로 block을 어디에 copy(배치)할 것인가?
(1) Direct Mapped(직접사상)
: 특정한 특성에 따라 연관지어서 주소에 따라 값의 위치를 정한다.
메모리 블록 주소를 상위계층의 한 주소에 바로 사상시키는 방법이다.
(2) Set Associative(집합연관)
: 직접사상과 완전연관의 중간 형태, 각 블록이 들어갈 수 있는 장소의 개수가 정해져있는 캐시(적어도 2곳 이상)
ex, 3학년은 3층 아무곳에 들어가세요.
(3) Fully Associative(완전연관)
: 블록이 캐시의 어느곳에나 들어갈 수 있는 캐시구조.
ex, 아무곳이나 들어가세요.
② block identification : 블록을 어떻게 찾을까?
- 원하는 블록이 있는지 없는지 찾는방법, "주소값"을 가지고 찾는다.
(1) 직접사상 : index(인덱싱)
(2) 집합연관 : index, 비교
(3) 완전연관 : 비교
③ block replacement : 캐시 실패가 발생하면 어느 블록을 교체할까?
ex, 하위레벨에서 상위레벨로 가져오는데, 이미 상위레벨에 데이터가 존재하면 어떤 기준으로 쫓아내야 할까?
(1) LRU 방식 : Least Recently Used, 최근에 가장 적게 사용된 것을 대체한다.
(2) Random 방식 : 랜덤으로 대체한다.
(3) FIFO 방식 : First In First Out, 첫번째로 들어온 것부터 순서대로 대체한다.

④ write policy(쓰기정책) : 쓰기는 어떻게 하는가?
다음 왼쪽 그림에서 메모리에서 copy하여 캐시에도 A라는 값이 들어있다고 가정하자.
이때, 캐시에서 A를 A'으로 바꾸면 메모리에서도 A를 A'으로 변경해주어야 한다.
(1) Write Through(즉시쓰기) : 상위레벨의 내용이 바뀌면 즉시 하위레벨도 즉시 직접 변경된다. Bus 권한을 갖고 있어야 하므로 부담이 크다. (접근시간↑)
(2) Write Back(=Copy Back, 나중쓰기) : 쓸 때는 캐시 블록의 값만 갱신하고, 나중에 그 블록이 교체될 때 하위 계층 메모리에 변경된 내용을 쓴다.
프로세서와 캐시

Data cashe : split 캐시
Shared cashe : 공유 캐시
Memory bus : 커뮤니케이션 링크
구조적 해저드를 방지하기 위해
메모리 : split 캐시로 instruction와 data를 구분
레지스터 : 한 주기에 따라 Read/Write 주기 구분
프로세서 파이프라인과 캐시
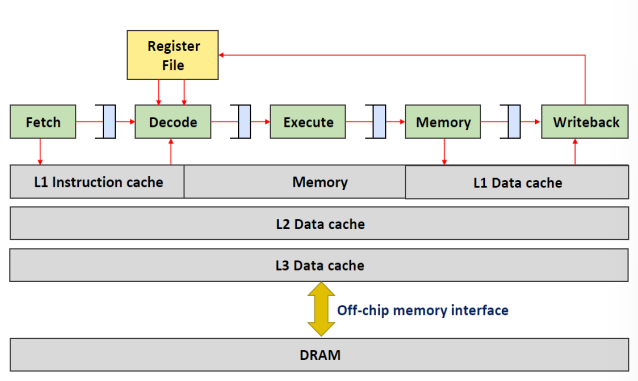

Caches in ARM Cortex-A53 and Intel Core i7
Intel Haswell i7 코어당 2개의 계층, 2개의 공유 계층
• L1 명령 및 L1 데이터: 32 KiB, 8방향 집합 연상
• L2: 256KiB, 8방향 세트 연상
• L3: 6MiB, 12방향 세트 조합
• L4: 128MiB, 16방향 세트 연상 eDRAM
'컴퓨터 구조' 카테고리의 다른 글
| Chapter5-3. 캐시 메모리 (0) | 2022.11.23 |
|---|---|
| Chapter5-2. 서로 다른 메모리 기술들 (0) | 2022.11.22 |
| Chapter.2-2 컴퓨터 언어 (0) | 2022.10.04 |
| Chapter.2-1 컴퓨터 언어 (0) | 2022.10.04 |
| Chapter.1 컴퓨터 추상화와 기술 (0) | 2022.10.03 |